

This has been a gap week in my meetings with research guru, Dr. Sarah Connell of Northeastern University's NULab. She knew she was going to have a full schedule of student meetings, so we agreed not to meet this week, but I asked for a homework assignment for the time until our next meeting, because I work well with assignments and deadlines. One more reason she is a great research guru, she had one in her backpocket: write a blogpost about a small but meaningful research discovery, not necessarily something I'd publish on, but something I would argue for. Because it is not yet the deadline (which is next Wednesday), I have of course not completed this assignment, but I spent a chunk of this week preparing to do the assignment, by which I mean, I decided to try out a script for cleaning the OCR in my Saturday Evening Post 1920-1926 collection.
One reason that I'm working with SEP at this stage is that lot of its OCR is not too bad:

But there are still passages that look like this:
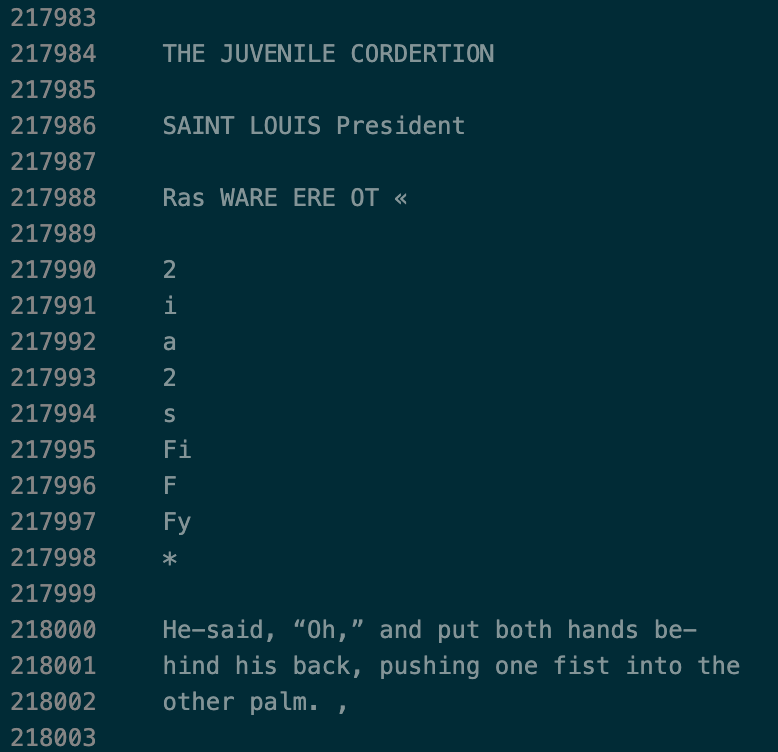
Is there a way to get rid of gibberish? I experimented with a couple, knowing full well they wouldn't be perfect, but curious about if they would improve results.
First try: check every word against the dictionary of English words proved in the Python library NLTK (natural language toolkit).
This removed far too many words, part of which I could fix by lemmatizing the words first (eg turning plurals into singulars, gerunds into base forms), because a lot of words lacked plurals in the dictionary.
Second try: lemmatize, then using a model someone built called Gibberish Detector, which takes in a string of characters and then decides if it is gibberish or not.
I thought this removed too few, believe it or not. There might be a training parameter I could tweak to try it again at some point--ie lowering my is it gibberish threshold so that more stuff looks like gibberish.
Third try: lemmatize, check each word in the dictionary, and if it's not in the dictionary, then check if it trips the Gibberish Detector. If it's in the dictionary, keep it. If it's not in the dictionary but also not gibberish, keep it.
This got rid of a lot of the straight up noise, but it got rid of a bunch of other stuff, too--most notably, names of people (although places did okay). I experimented with running a Named Entity Recognition on my text to get a list of proper names that were in it, but it took a long time and didn't add much. This again, though, is something I could continue tweaking.
Despite these issues, I decided to go with this third try for now, and to get rid of numbers while I was at it. More on that in a minute.
So, I then trained a word vector model for my SEP corpus as downloaded and another one for my noise, number, and name averse corpus.
The next step is to compare them: is the more filtered corpus creating a better model? Perfectly accurate is not an option, at this time: either I'm going to have totally uncorrected OCR or OCR with fewer outright errors but also missing proper names.
One way of quantifying this, the SEP original download model (let's call it Model O for original) has 106545, and the filtered model (let's call it Model F for filtered) has 85911 rows. That means the original download produced 106k distinct combinations of character strings (some of which were words from the magazine, some of which were numbers, and some of which OCR gibberish) and the filtered model had about 21k fewer. That seems like a lot. But we know that number includes numbers and people's names, and I also know there are a lot of numbers in the original files. So there are definitely legitimate, informative things the filtered version won't have, but will it better represent other things because those things are taken out?
One thing that I'm constantly keeping in mind as I look at word vector results: vectors are NOT showing us what words co-occur around each other. They are showing us what words tend to occupy the same semantic space. Put another way, it's not showing us what other words are in the sentence with a given word. It's showing us what words have the same spot in similar sentences.
Since word vectors show us what words tend to have the same types of semantic positions, one quick and dirty validation technique is to try out days of the week, months of the year, and foods. Looking at the closest terms for January should yield a list of months, which may or may not include May:
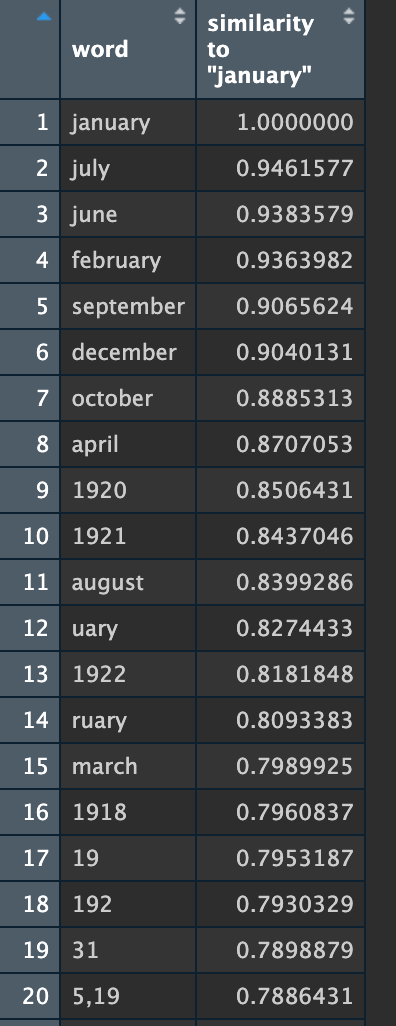
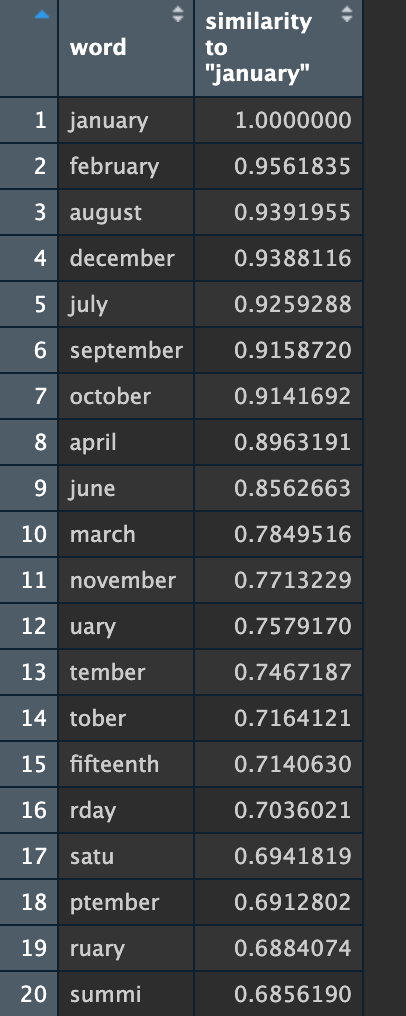
Both models seem sound, although you can tell from these lists 1) that my cleaning script still left a lot of mis-scanned words and 2) there's a lot of numbers in the originally downloaded files.
Both models having passed basic validation, as a first pass, I generated term clusters for each model. That means I ran a chunk of code that looked at the whole vector space of the model--ie, at graph of each word's position in 100-dimensional space--and marked off 150 subspaces in which certain terms were closer to each other than they were to other terms. This is going to come out slightly differently each time, because the starting points the algorithm picks are random, but there's enough consistency to be able to get a good sense of pockets of words that share meaning.
At first glance, Model O had about 14 noise or number dominated clusters and Model F had about 10--a little less than a third fewer.
Now to take a look at how the models compare for specific terms. What do each of them show as the word most similar to "car"?
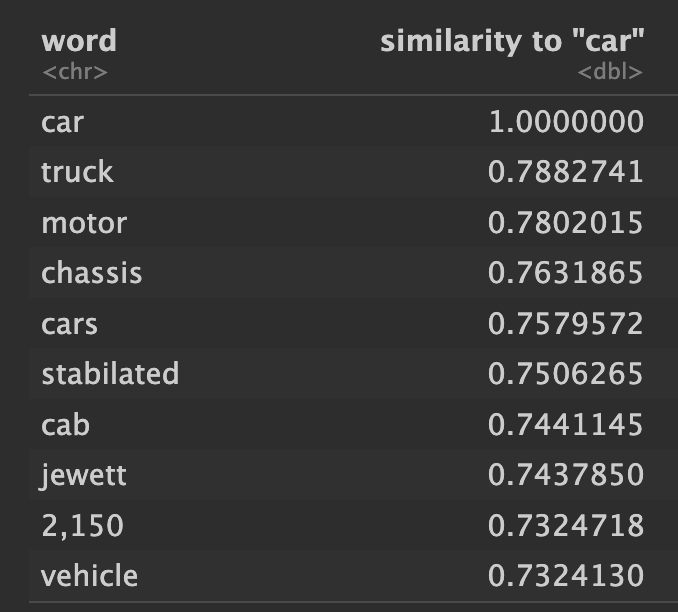
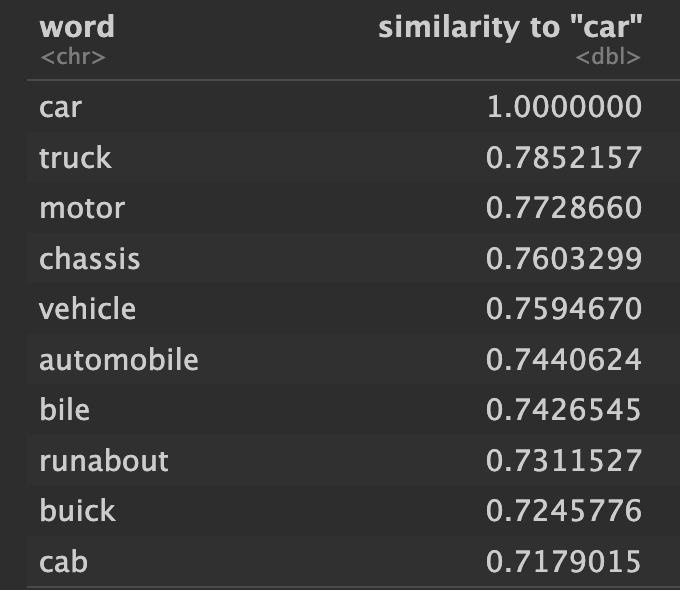
Pretty similar.
How about the bigger "car" vector that I developed, grouping terms related to cars as a thing but subtracting car brand names?
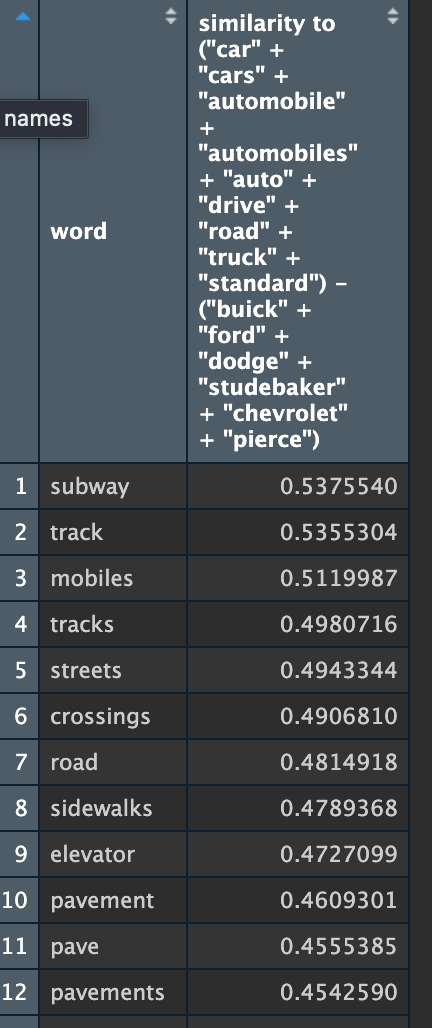
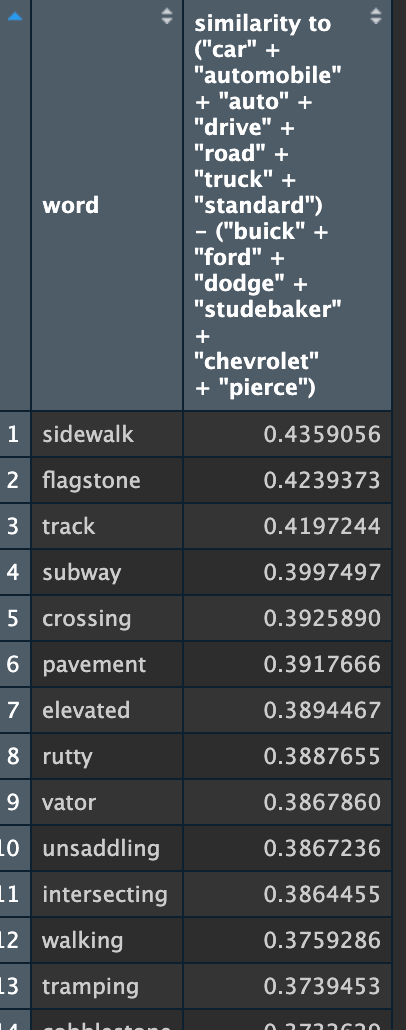
Also pretty similar, once I figured out that including any plurals in the query would break the model in which there were no plural words in the model (F). Note that if you take out car brand names, even keeping “automobile” in, the connectedness of “car” to “train” and therefore transportation in general (including human elevators and horses) becomes way more clear.
How about visualizing the vector space of all the car words, brands included, together?
This is one I'm really curious about, because Model O's visualization looked like this:
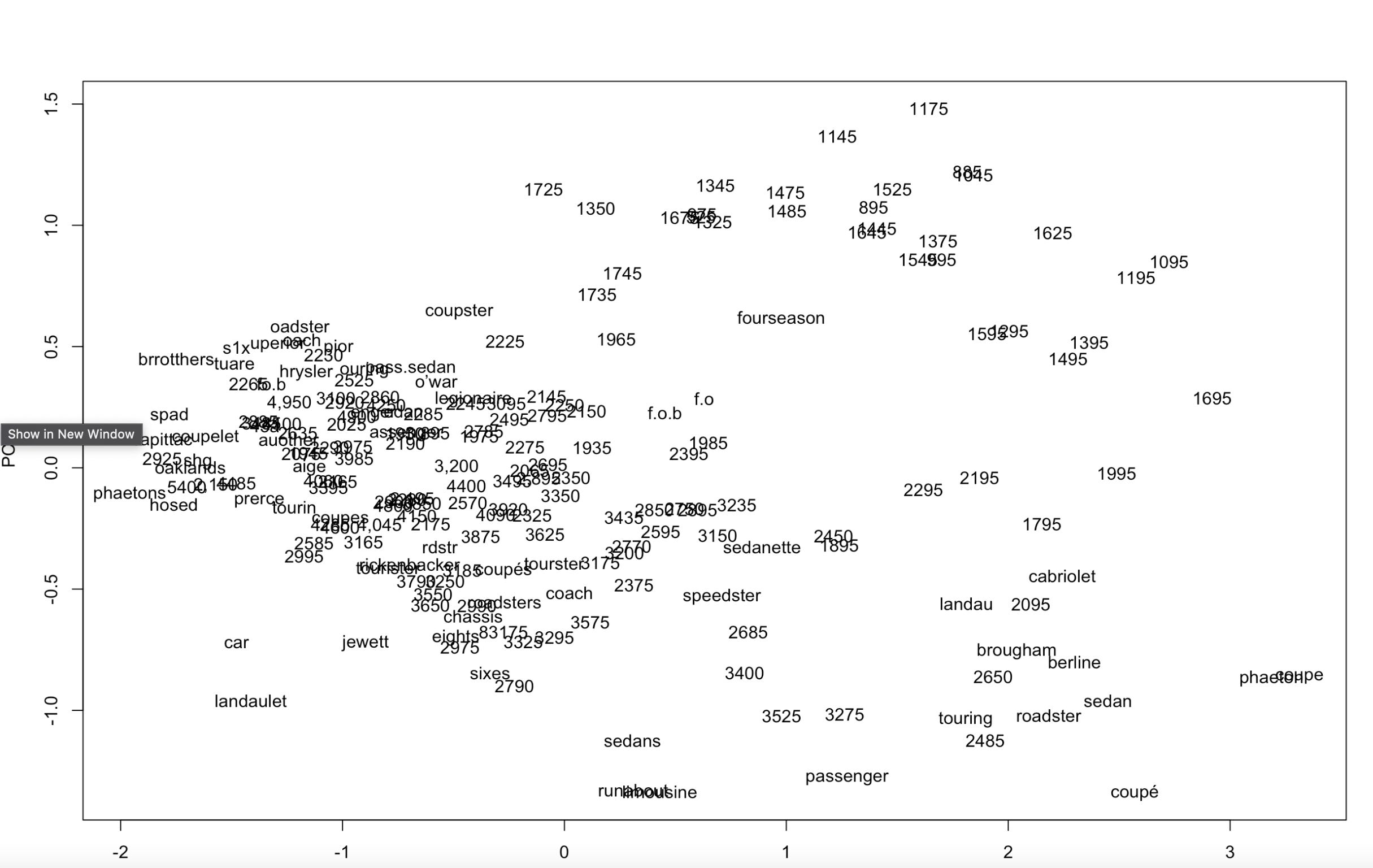
At first, I assumed those numbers were noise or dates or page numbers, but when I took a closer look, I realized these were prices. That clued me in to the prevalence of ads for cars, but numbers were taking up a lot of space that I wanted to be seeing words in.
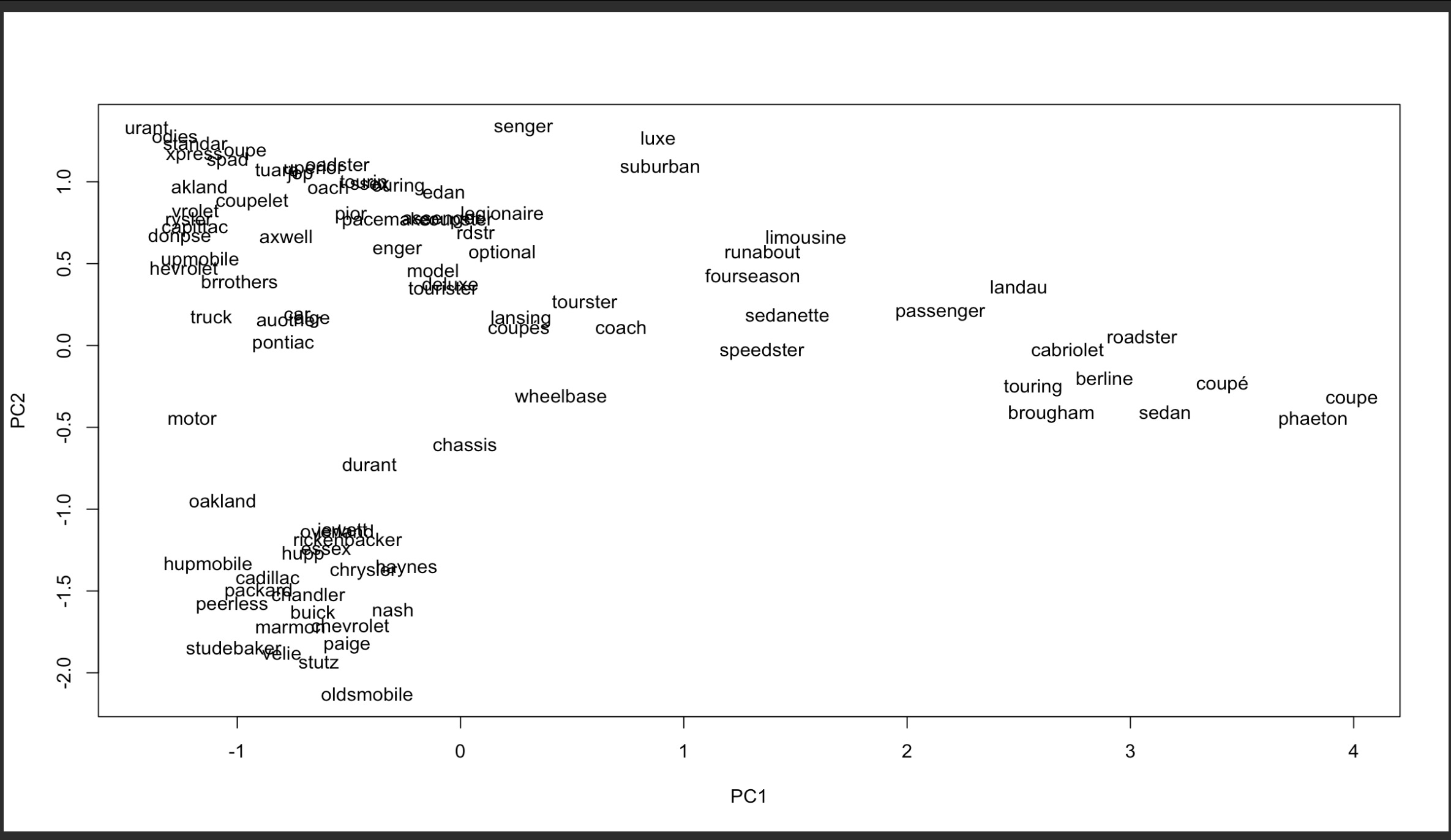
Well, it looks like it's more or less the same words, somewhat more legible now that there aren't a ton of prices.
Okay, last one: let's look at a more thematically interesting word for studying US literatures: what do the two models show as the words closest to 'america'?
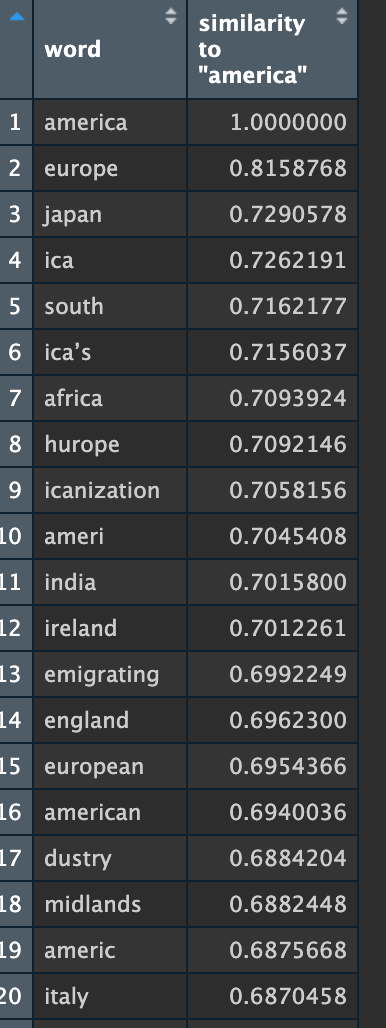
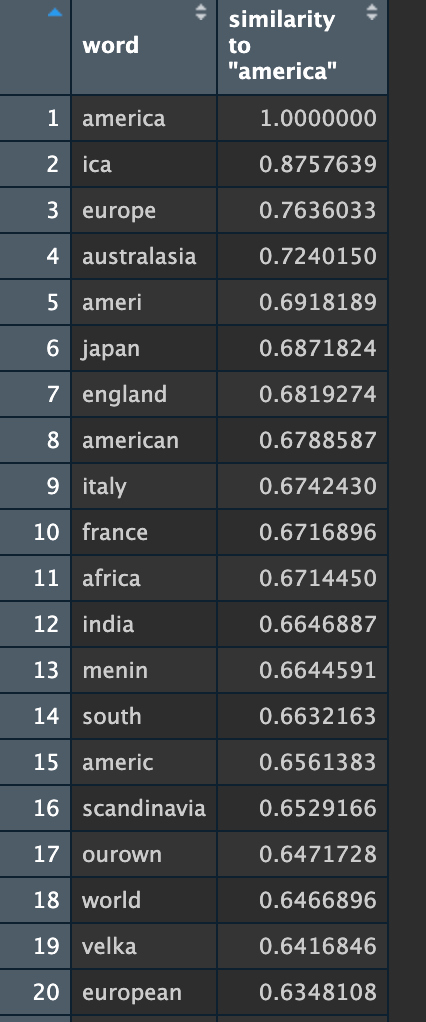
Here, I see meaningful differences: while Model O clearly has OCR errors, they are interesting and usually decipherable ones. For example, "dustry." Clearly, that's "industry", but for whatever reason, the 'in-' is getting cut off more often than not, so "dustry" is turning out to be the token getting counted. Same with "icanization" --that's a cut off "americanization," a really interesting modernist topic! The results for Model F are dominated by correct but repetitive words--mostly other countries. Which to be fair, the Model O list is dominated by countries, too. But some other ideas got captured as well, in forms that tripped the gibberish filter but that I can still, as a human, read.
Verdict: not to clean. As Rawson & Munoz had already told us! But at least for this corpus, I feel more confident now that unfiltered OCR words are actually better for getting at semantic space, because the noise isn't so consistent that it's rising to the top of spaces I'm interested in, and I can decipher a lot of the mistakes. It's probably worth it to have a version of the model that takes numbers out to look at cars. I can also do a better job with undoing hyphenation.
This is part of digital work, especially of the textual variety: you try a lot of things, and some of them don't turn out to be as useful as you'd hoped, but at least you know, and for us humanists, you got some more practice coding.
Brilliant analysis, written in lay terms. Thank you.